核心概念
使用 BeeFog 前,了解系统中最重要的几个概念。
雾计算(Fog Computing),是使用最终用户终端设备或连接最终用户设备的边缘设备, 以分布式协作架构进行数据存储(相对于将数据集中存储在云数据中心), 或进行分布式网络数据包传输通信(相对于透过互联网骨干路由), 或进行分布式信息处理(相对于在云数据中心集中处理)。 雾计算是由思科(Cisco)在2014年所提出的概念,为云计算的延伸,这个架构可以将计算需求分层次、分区域处理,以减少对于网络带宽的浪费。
BeeFog 是一个开源的雾计算框架,侧重于解决雾节点和用户终端设备的连接和计算任务分发。 BeeFog 的计算任务侧重于网络传输任务和信息处理任务,不会涉及分布式存储。 在雾节点之上,是您处在云端的业务系统,如下图所示:
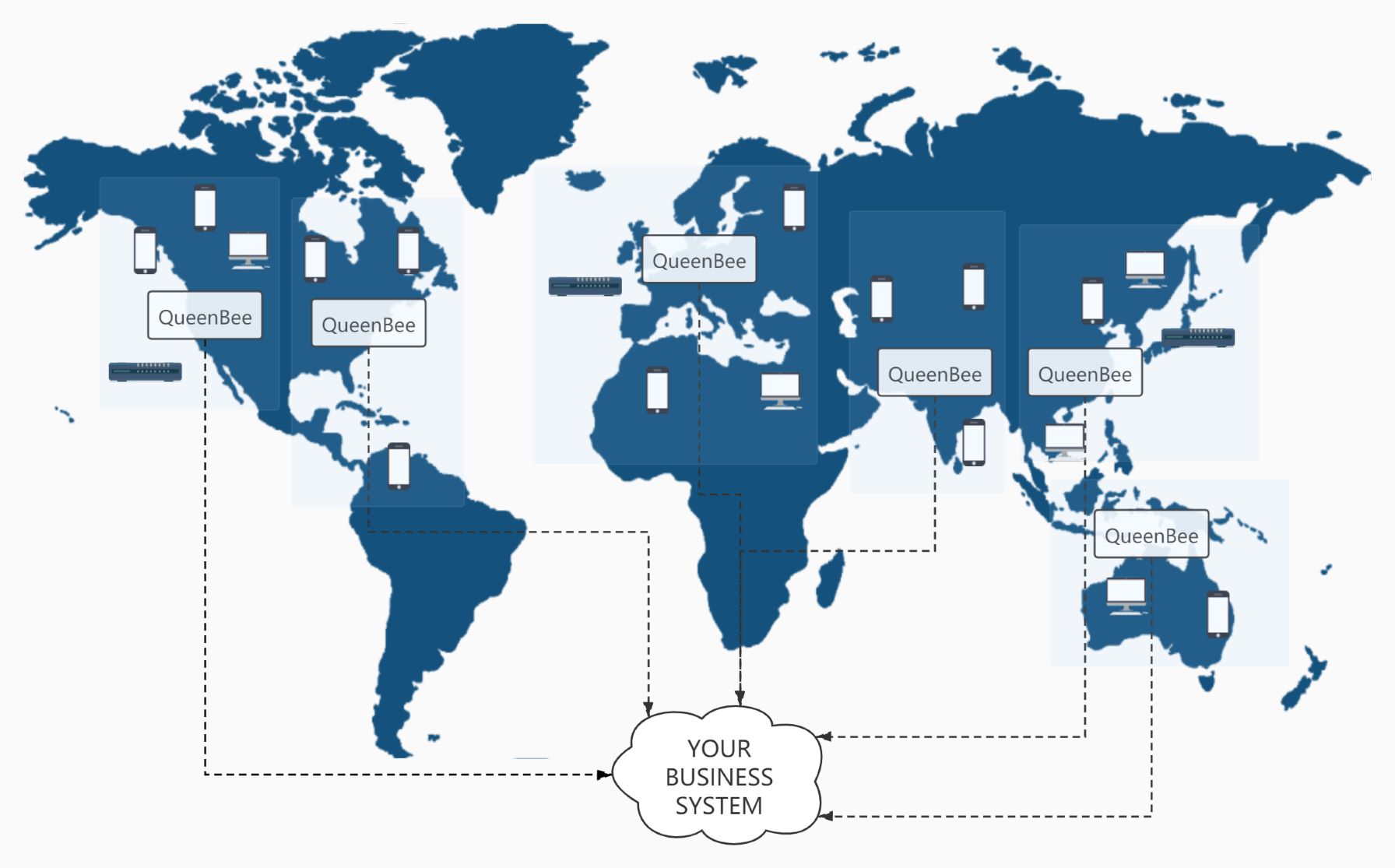
我们把一个地区的雾节点叫做 QueenBee ,主要负责任务调度和分配。把分布式的工作设备叫做 WorkerBee,主要负责执行计算任务。
WorkerBee 会持续主动向 QueenBee 请求任务,如果任务池中有需要执行的任务,就会取回执行。
由于雾计算框架现在还没有成熟的开源实现,不在这里一一对比,列举一些我们的特性:
计算意义很宽泛,可能包括网络请求、数据处理或人工智能训练等等。撰写中……
虽然 BeeFog 可以适应任何场景的爬虫任务,但有的场景会比其他框架有显著优势:
BeeFog 可以将任务进行地理位置分布,就近执行和网络请求有关的任务,将传输往云端的数据量减少到最少,避免网络带来的问题。
比如在爬虫场景,有时爬虫提取的内容甚至不会高于原始内容的1%。这个比例越悬殊,使用雾计算越有优势。
您至少要阅读本章的概述文档了解基本的概念,然后阅读"快速开始"章节就可以上手使用了。在需要更高级的特性时,有选择的阅读剩余的文档。